Fine-Grained Video Retrieval with Scene Sketches
|
Ran Zuo1,2
|
|
Keqi Chen1,2
|
Zhengming Zhang1,2
|
|
Yu-Kun Lai3
|
Fang Liu4
|
Cuixia Ma1,2
|
Hao Wang5
|
|
Yong-Jin Liu4
|
Hongan Wang1,2
|
|
1Institute of Software, CAS
|
2UCAS
|
3Cardiff University
|
4Tsinghua University
|
5Alibaba
|
|
|
|
The application scenario of fine-grained scene-level sketch-based
video retrieval (SBVR), where different types of sketch queries are compared:
(a) coarse-grained sketch without appearance details, infeasible for accurate
retrieval; (b) fine-grained sketch(es) without background elements, limited to
single instance; (c) fine-grained scene-level sketch, providing sufficient visual
descriptions for accurate video match.
|
Abstract
Benefiting from the intuitiveness and naturalness
of sketch interaction, sketch-based video retrieval (SBVR) has
received considerable attention in the video retrieval research
area. However, most existing SBVR research still lacks the
capability of accurate video retrieval with fine-grained scene
content. To address this problem, in this paper we investigate
a new task, which focuses on retrieving the target video by
utilizing a fine-grained storyboard sketch depicting the scene
layout and major foreground instances’ visual characteristics
(e.g., appearance, size, pose, etc.) of video; we call such a
task “fine-grained scene-level SBVR”. The most challenging
issue in this task is how to perform scene-level cross-modal
alignment between sketch and video. Our solution consists of
two parts. First, we construct a scene-level sketch-video dataset
called SketchVideo, in which sketch-video pairs are provided and
each pair contains a clip-level storyboard sketch and several
keyframe sketches (corresponding to video frames). Second, we
propose a novel deep learning architecture called Sketch Query
Graph Convolutional Network (SQ-GCN). In SQ-GCN, we first
adaptively sample the video frames to improve video encoding
efficiency, and then construct appearance and category graphs
to jointly model visual and semantic alignment between sketch
and video. Experiments show that our fine-grained scene-level
SBVR framework with SQ-GCN architecture outperforms the
state-of-the-art fine-grained retrieval methods. The SketchVideo
dataset and SQ-GCN code are available in the project webpage
https://iscas-mmsketch.github.io/FG-SL-SBVR/.
Dataset
|
|
|
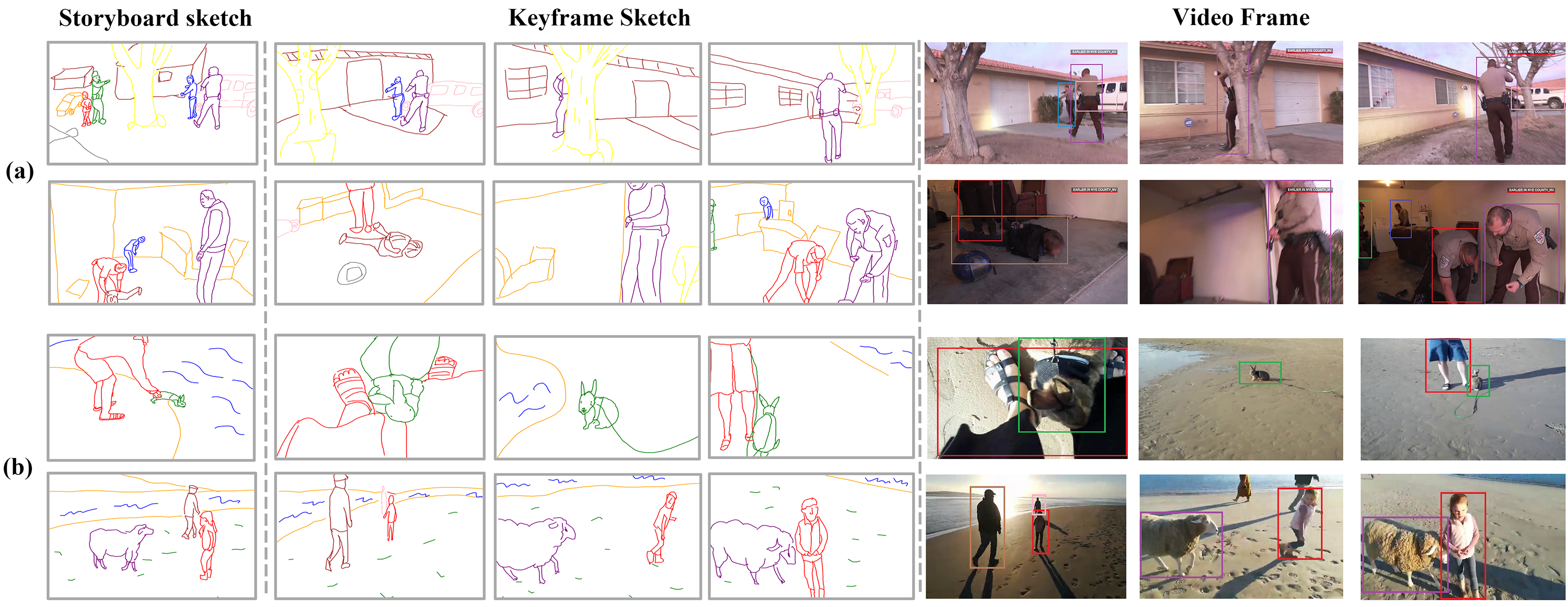
Examples of our SketchVideo dataset where the sketches and video frames are temporally colored to show the dynamics of the individuals over time.
Besides the fine-grained diversity in objects’ size, viewpoint and appearance, the dataset also has fine-grained scene variations: (a) background variation, where
the two videos contain the same policemen and fugitive outside and inside a house respectively; (b) foreground object variation, where there are different
individuals on the beach in two videos.
|
Network Architecture
|
|
|
The pipeline of our SQ-GCN for fine-grained scene-level SBVR with storyboard sketches. Our network includes three components, i.e. storyboard
sketch encoding, video encoding and feature matching. We firstly use an adaptive video frame sampling strategy to select relevant video samples. Then we
construct appearance graphs (appearance and position features) and category graphs (category and position features without scene node) for both sketch and
video. Through GCN for sketch encoding and ST-GCN for video encoding, we embed sketch and video into a common feature space, and use a triplet network
for training.
|
Paper and Code
Ran Zuo, Xiaoming Deng, Keqi Chen, Zhengming Zhang, Yu-Kun Lai, Fang Liu,
Cuixia Ma, Hao Wang, Yong-Jin Liu, Hongan Wang
Fine-Grained Video Retrieval with Scene Sketches.
IEEE TIP, 2023.
[Paper]
[Bibtex]
[Code]
[Dataset]
The code and dataset are coming soon.
|
|
Acknowledgements
This work was supported by the National Natural Science Foundation of
China under Grant 62272447, the Natural Science Foundation of Beijing
under Grant 4212029, Newton Prize 2019 China Award under Grant
NP2PB/100047, and Beijing Natural Science Foundation under Grant L222008.
The websiteis modified from this template.
|